Test Data Architecture
How to build a test data architecture that works
Being an architect involves developing something that caters to the needs and requirements of your client. For instance, when planning a new house, you must consider various factors. Is it essential for the house to be earthquake-resistant due to the location? Or, in our case as Dutch residents, should it be designed to float? Additionally, you must decide if it should be a single-story house or if you prefer multiple floors. It’s crucial to determine your time frame and budget as well. All these questions are pertinent when constructing a house.
The same principles apply to building a test data architecture. Before embarking on the journey of constructing or designing a test data platform, you should ponder the same questions from a test data perspective.

In general, we all encounter similar challenges: time constraints, performance issues, and the need for speed, or at least the absence of these elements. Delivering software quickly is crucial, which is why the prompt delivery of test data becomes essential. Therefore, when designing or building your test data platform, always prioritize the rapid delivery of test data!
Single Storey House
In an ‘ideal’ IT world, designing a ‘test data’ house might be as simple as planning a single-story structure. Let’s draw a parallel with an IT environment that has a single-source production database – essentially, a straightforward house. However, this simplicity can quickly give way to complexity, much like when the requirement is to make it entirely climate-neutral. Similar challenges emerge in the realm of test data.
In a simplified scenario with a single-source database, managing test data appears straightforward. It allows for smoother deployment to QA or Dev environments, especially during the early stages of development, such as unit tests, where test data requirements are, in most cases, not overly complex.
However, as testing progresses, the demand for more comprehensive and complex test data rises. For instance, when conducting regression or integration tests, the necessity for intricate and representative test data becomes significantly pronounced, as depicted in the graph below.
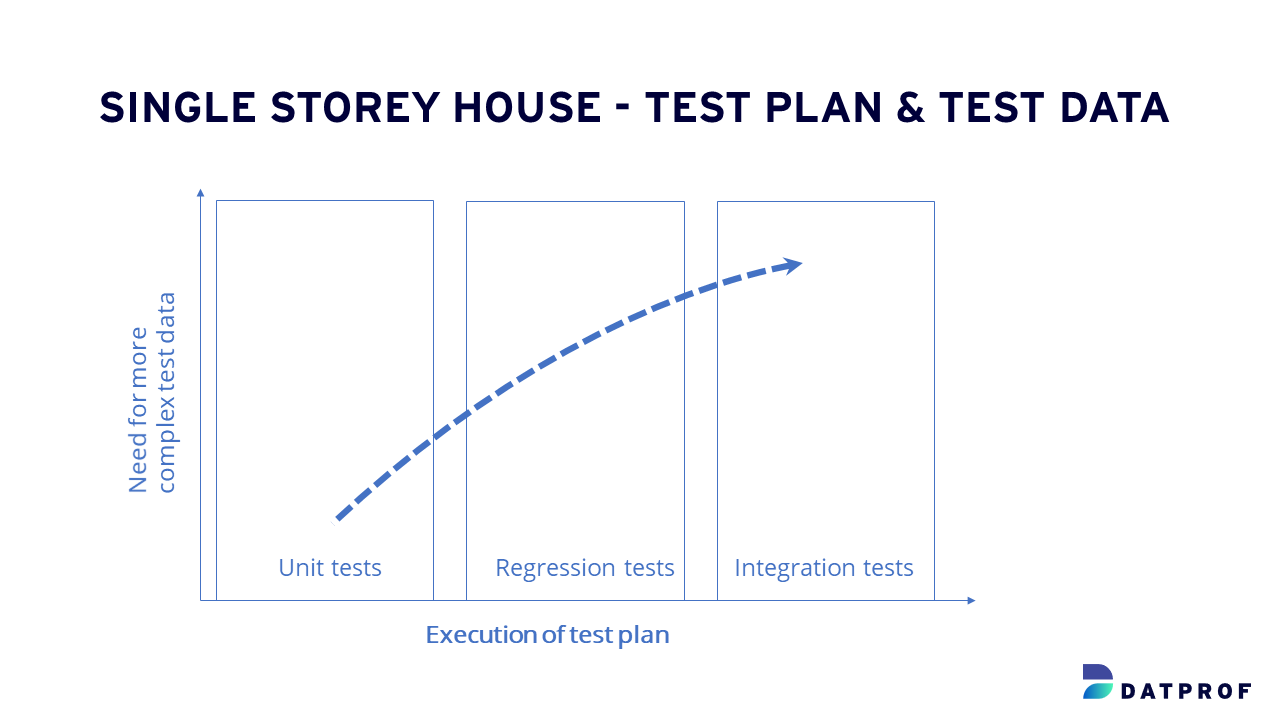
Test Data Architecture: A Single-Storey House
So, how do you go about managing test data in this context? How can you ensure that test data is readily available in a straightforward IT environment? Developing a test data architecture can be a relatively straightforward process, although challenges may arise along the way. The key is to start at the beginning and ask yourself, ‘What’s not working with our current test data house?’
There could be several bottlenecks in the design of your existing test data architecture, such as:
- Compliance: Your current setup may not comply with regulations.
- Representativeness: The test data you have might be outdated, dating back several years.
- Time-Consuming Database Operations: Creating or refreshing a test database takes a significant amount of time.
- Efficiency in Finding Test Data: It may be time-consuming to locate the right test data that aligns with your test cases.
Many of these bottlenecks can be addressed by simplifying the process of creating and deploying new Dev or QA databases. Often, organizations struggle with refreshing a test database, a process that consumes both procedural and technical time. As a result, development and test engineers may avoid interacting with the test database, settling for the status quo.
The critical question to ask is, ‘What’s wrong with the current test data architecture?’ By enhancing speed and finding ways to effortlessly create refreshed QA databases, you can tackle some of these bottlenecks head-on. This approach has the potential to make a substantial impact on your test data management.
The Time Bottleneck
As previously highlighted, speed is of paramount importance when it comes to test data delivery. The question that often arises is: How can we make test data available with minimal effort? However, the challenge lies in the size and complexity of production databases, which can hinder the seamless delivery of test data.
Restoring a large database, especially from a technical standpoint, can be an exceptionally time-consuming process. Just to give you an idea, restoring and backing up a 10 Terabyte database could take up to 12 hours (source: StackExchange).
These figures might not come as a surprise to many of us, especially in corporate settings where dealing with sizable databases is the norm. In fact, you might find yourself working with even larger databases.
Regrettably, the situation can exacerbate further. Research has shown that obtaining the right test data can, in some instances, extend to multiple days, and in some cases, even weeks! This delay may be attributed to procedural bottlenecks, as acquiring all the necessary approvals and permissions can be a time-consuming process.
Effortless Test Data Delivery Through Subsetting
Especially in the early stages of development, there’s a strong desire for test data that’s easy to deploy and reusable. Consider this scenario: you run a test, gather results, implement a fix, and then rerun the test. Ideally, you want to use the exact same test data as in your initial test. Why? Because if the fix works, you want to be sure it’s due to the fix itself and not because of any data-related issues. To verify the fix, consistency in test data is key.
However, the reality is that restoring and backing up a massive 10-terabyte database or waiting a long time to get back to the original starting point is far from ideal. That’s where having a compact test data subset can significantly simplify your life. Backing up and restoring a small test data subset can be accomplished in minutes, allowing you to execute tests with the same data.
But how can you ensure the availability of the exact same test data set from an architectural perspective? We commonly see two approaches:
- Backup from an Earlier Subset: Creating a backup from a previously generated subset. Since the subset is, for instance, only 100 gigabytes instead of 10 terabytes, it can be swiftly and effortlessly restored in mere minutes.
- Start a New Subset Process: Initiating a new subset process from the same source. It’s essential to note that the source data shouldn’t have undergone any changes.
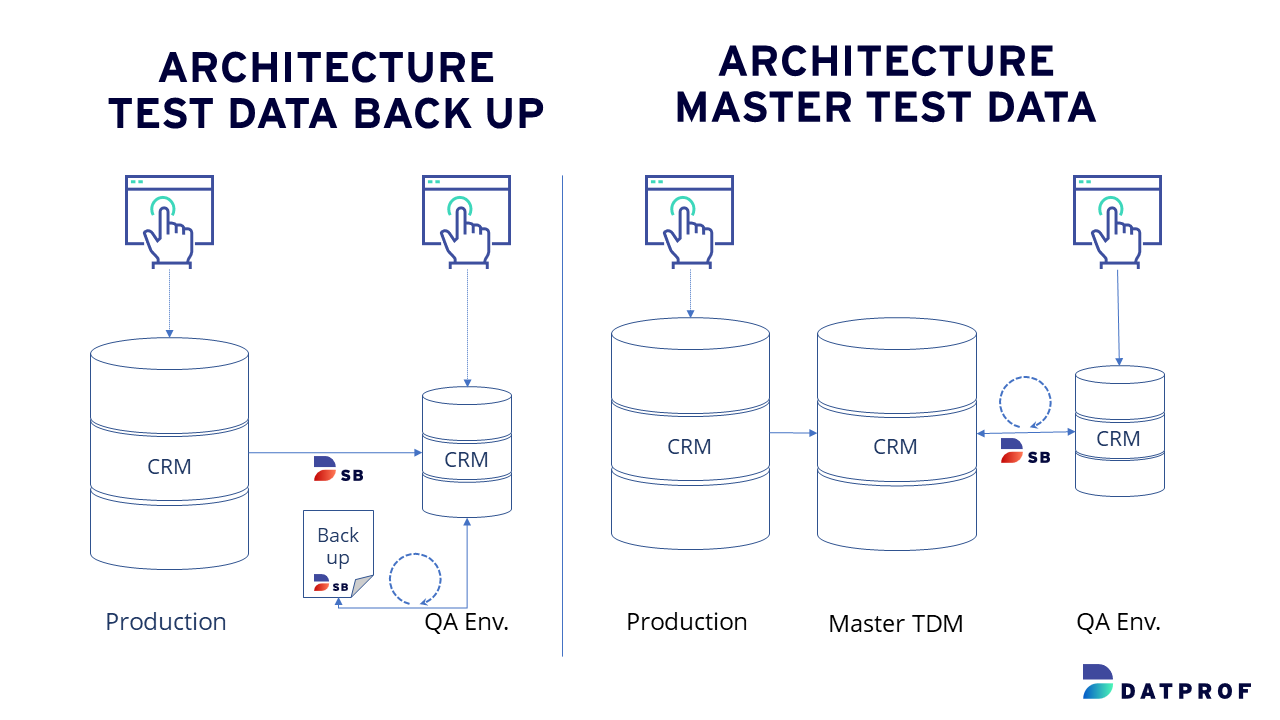
In both test data architectures, you can run a test multiple times using the same test data set. I personally prefer the ‘backup and restore’ strategy because it ensures the consistency of the test data set over time.
Designing Your Test Data Architecture?
Our whitepaper guides your decision-making process in designing and provisioning test data for lower environments. It can also bolster your business case for investing in Test Architecture.
Managing Test Data for Integration Tests
Now, let’s delve into the realm of integration tests. How do you go about handling test data for these crucial tests that involve multiple dependent applications? When conducting integration tests, you introduce more interconnected systems into the mix. So, how can you ensure the consistency of your test data across these various applications?
The key challenge in integration testing lies in achieving and maintaining consistent test data across multiple databases and systems. This challenge arises whether you’re masking or generating data, subsetting, or virtualizing test databases. It’s essential to have a uniform test data set that aligns seamlessly across these diverse systems.
While using full-size, non-anonymized copies for integration tests is an option, it may not always be practical, especially if compliance is a requirement. Masking the database is a common solution, but it doesn’t address the speed and delivery issues.
In essence, the crux of the matter lies in achieving test data consistency across multiple databases and systems.
Resetting Test Data for Integration Tests
What happens when an integration test fails? Naturally, you’d want to reset the test data to its original state, just as you do during regression tests. But how can you manage this effectively? One approach could involve refreshing the database from the original production source. However, this option may consume a significant amount of time, making it less than ideal.
If refreshing from the original source isn’t feasible, you’ll find yourself searching for a test data set that appears identical. However, appearances can be deceiving, especially in complex data environments, which are common in large corporate core systems.
These complex data systems often present data quality challenges, which can significantly prolong the search for even somewhat comparable test data. Research indicates that searching for suitable test data can consume up to 75% of your total testing time.
To address this challenge, it becomes increasingly valuable to be able to reset your test data to its original values swiftly. Subsetting can be a powerful tool in achieving this, allowing you to reset data to precisely the same starting point in minimal time. The primary challenge in integration tests lies in maintaining a consistent subset of test data across multiple systems.
Achieving Test Data Consistency for Integration Testing
There are several methods to ensure test data consistency across multiple systems:
- Service Virtualization: Employing service virtualization allows you to virtualize dependent services in your system under test. You may need to populate test data into these virtualized services.
- Subset Related Systems: Alternatively, you can subset related systems to ensure that the data in your test database aligns with the test data in the system under test.
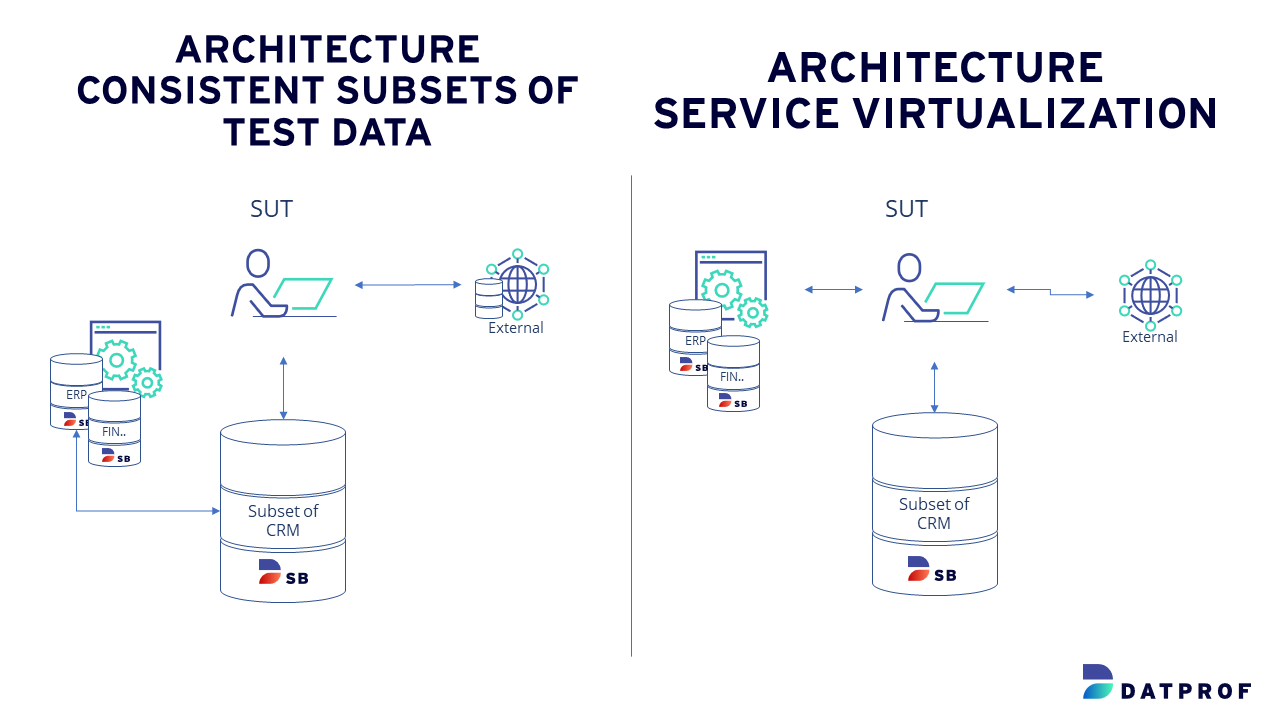
Building Your Test Data Architecture
This blog offers a simplified perspective on developing your test data architecture—a foundation for your ‘house’ of successful testing. By focusing on key principles, you can enhance test data availability and streamline your testing processes.
For a deeper dive into building a sustainable test data architecture, download our free whitepaper below. Explore advanced strategies and practical insights to empower your testing efforts.
Download free whitepaper
Building a sustainable test data architecture
Paper - Test Data Architecture
"*" indicates required fields
