Data subsetting
Verschuiving naar agile softwaretesten met data subsets
We streven er allemaal naar om de time-to-market van onze software te verkorten. Met dit doel voor ogen beginnen we met het automatiseren van tests, ontwikkelen we in agile/scrum teams, starten we met continuous delivery etc. Al deze methodes kunnen succesvol zijn – kúnnen. De successen van deze methodes zijn afhankelijk van je oude architectuur en infrastructuur. We moeten innoveren op de manier waarop we onze huidige infrastuctuur gebruiken. De architectuur van de DTAP die we tegenwoordig gebruiken, is sinds het begin van de jaren negentig niet significant veranderd. Softwareontwikkeling is echter wel behoorlijk veranderd, waardoor we onze niet-productie omgevingen en de bijbehorende architectuur moesten innoveren.
Test data voorbereiding
Wat is data subsetting?
Test data subsetting is het extraheren van een (referentieel integer) kleinere dataset van productie naar een niet-productie omgeving. Veel klanten vragen ons: “Hoe moeten we een subset maken?” en “Hoe bruikbaar is een subset vergeleken met mijn kopie productie?” Het concept van subsetten van gegevens is verrassend eenvoudig: neem een consistent deel van een database en draag het over naar en andere database. Dat is alles. Natuurlijk is het eigenlijke subsetten niet zo eenvoudig. Vooral het selecteren van de juiste gegevens voor de taak is lastig, of het nu gaat om testen of ontwikkelen. Waarom? Omdat je gegevens moet filteren. De moeilijkheid zit hem in het verkrijgen van alle juiste data om een consistente dataset over alle tabellen te maken die ook voldoet aan de behofte van de testers.
Waarom data subsetten?
Momenteel gebruiken de meeste organisaties kopieën van productie voor testen en ontwikkelen. Desgevraagd gebruiken deze organisaties hiervoor vaak argumenten als: “Dit is de gemakkelijkste manier van werken.” of “Alleen productiedata bevat alle testgevallen.” of “We kunnen alleen grondig testen met productiedata”. Deze argumenten kunnen in sommige (test)gevallen geldig zijn, maar er zijn genoeg redenen om geen volledige kopieën van productie te gebruiken:
- De beschikbare time-to-market wordt korter omdat ‘de business’ erom vraagt en de levenscyclus van software verkort ook.
- Methodes zoals Scrum, Agile of DevOps zijn meestal gericht op het sneller leveren van de juiste software. Snellere levering vereist echter hogere eisen aan omgevingen om dit te ondersteunen. Grote (soms enorme) kopieën van productie helpen hier niet bij, werken dit eerder tegen.
- Je productie ongeving groeit in de loop van de tijd, de benodigde grootte in niet-productie omgevingen groeit twee keer zo snel als je volledige kopieën van productie blijft gebruiken. Bijvoorbeeld: als je productie-omvang groeit van 1 terabyte naar 2 terabyte, resulteert dat in: 2 TB acceptatie + 2 TB test + 2 TB ontwikkeling = 6 TB toename buiten productie om.
Zonder twijfel kunnen we stellen dat de meeste organisaties al deze opgeslagen data in niet-productie niet nodig hebben. Het kost alleen maar onnodig geld.
Met het gebruik van subsets:
- Neemt de behoefte aan dataopslag af (soms met meer dan 90%)
- Niet-actieve (wacht)tijd wordt aanzienlijk verminderd
- Hoge controle bij doorlooptijd van test en ontwikkeling
- Ontwikkelaars beïnvloeden de data die ze nodig hebben
Een subset creëren
Dus hoe creëren we een bruikbare subset? Als eerste moeten we de manier waarop we naar (test)data kijken, veranderen. We moeten data op dezelfde manier bekijken als de wetenschap. Het is gewoon niet haalbaar om een hele populatie te interviewen, dus we hebben een steekproefpopulatie nodig die representatief is. Op basis van die steekproef kan iets worden gezegd of besloten over de volledige populatie. Hetzelfde geldt voor (test)data. Kies testdata zorgvuldig als een representatief voorbeeld en gebruik het. Meestal vereist dit wat aanpassingen, maar experimenteer (test) en leer van de resultaten!
Veel van onze klanten gebruiken filters op basis van een aantal goed bekende testcases en indien nodig worden die aangevuld met een willekeurig percentage van productiedata. Zoals je kunt zien, is de kern van de subset gevuld met bekende testcases, dus gebaseerd op kennis afkomstig van de testers en ontwikkelaars. Uiteindelijk beïnvloeden ontwikkelaars en testers dus hun testdata. Vaak resulteert dit in een kleinere dataset. Met DATPROF Subset zien we dat het mogelijk is om een productiedatabase van 6 terabyte te verkleinen tot 60 gigabyte!
Test data preparatie tools
Met DATPROF subset kun je specifieke selecties uit productiedatabases extraheren en deze direct beschikbaar maken binnen de testomgevingen. DATPROF Subset selecteert gegevens uit een volledige productiedatabase, de source database. Deze data gaat naar een kopie (test) database, de target database. Door filters toe te passen bij het vullen van de target database, zal deze database kleiner zijn dan de source database. Dit maakt sneller en goedkoper testen mogelijk.
Data extractie methodes
De belangrijkste methode die DATPROF Subset gebruikt, is het toegang krijgen tot de data via één centrale tabel in de database: de starttabel. Andere gegevens worden geëxtraheerd op basis van een foreign key relatie met de starttabel. Tijdens de inzet van het Subsetproject is alleen een verbinding tussen de source en target database nodig. Er komen geen gevens door DATPROF Subset heen. Dit heeft een gunstige invloed op de prestatie.
Data preparatie voorbeelden
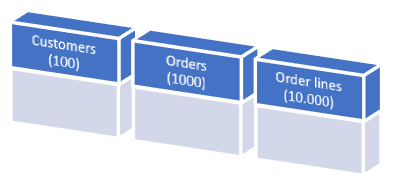
Het voorbeeld rechts toont 3 tabellen. Er zijn 100 klanten, 1000 orders en 10.000 orderregels in de source database. Elke klant heeft 10 bestellingen en elke bestelling heeft 10 gerelateerde order_details. Slechts 10 klanten hebben een naam die begint met de letter A.
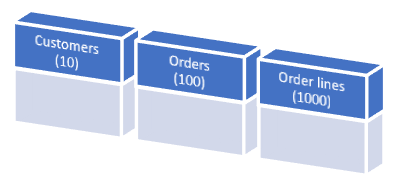
Als de klantentabel de starttabel is en we alleen klanten selecteren met een naam die begint met de letter A, resulteert dit in een doeldatabase met 10 klanten, 100 orders en een totaal van 1000 order_details.
Het resultaat is dat de target database maar liefst 90% kleiner is dan de source database, met behoud van de dataconsistentie.
Data extractie tips
Met DATPROF Subset kan de gebruiker filters en functies opslaan, zodat ze vaker dan één keer kunnen worden geïmplementeerd. Op deze manier onstaat een gecontroleerd en gestructureerd subsetproces. Na het subsetten kunnen de gegevens in de target database worden gebruikt voor testdoeleinden, maar ze kunnen ook de basis vormen voor data anonimiseren met DATPROF Privacy.
Bekijk DATPROF Subset
Technical Product Demonstration
Subset de juiste hoeveelheid test data en verminder de opslagkosten en wachttijden voor nieuwe testomgevingen.