Test Data Automation
De missie van DATPROF is het verbeteren van de toegankelijkheid en beschikbaarheid van test data voor software-ingenieurs – ontwikkelaars, testers en QA, evenals het trainingsteam. Ons motto is “De juiste testdata op de juiste plaats op het juiste moment”. We hebben dit besproken in ons artikel over Continuous Test Data, dat de vraag naar Test Data Automation voedt. Dit artikel laat zien hoe Test Data Automation helpt bij het realiseren van de ambitie van snellere softwareontwikkeling door de inzet van test data sets te automatiseren.
Elk project heeft test data nodig. Deze behoefte kan en zal waarschijnlijk verschillen tussen projecten. Soms zijn transactiegegevens de kernbehoefte: alle facturen van de afgelopen 6 maanden. Soms is het meer een representatieve steekproef van het klantenbestand: alle klanten in “deze lijst” met de bijbehorende transacties. Maar het verkrijgen van test data voor je project kan soms een strijd zijn, een uitdaging, misschien moeten we het echt noemen wat het is – een probleem. Dus hoe kunnen we dit probleem oplossen? Dit is waar Test Data Automation helpt!
Waarom test data automation?
Een van de belangrijkste redenen waarom automatisering van test data op je backlog zou moeten staan, is dat als je deze eenmaal hebt geïmplementeerd, je de leveringscycli van je releases enorm zult optimaliseren. Onderzoek toont ons aan dat een aanzienlijk aspect van de softwareontwikkelingstijd (gecombineerd ontwikkelen en testen) verloren gaat door te wachten tot de juiste test data beschikbaar komen. Het wachten op de juiste test data duurt gemiddeld meer dan 5 werkdagen, VIJF! Op basis van onze ervaring denken we dat zelfs dit optimistisch zou kunnen zijn. We hebben gezien dat het soms enkele weken duurt om de juiste test data te verkrijgen …
Dus waarom duurt het zo lang om een testgegevensset te krijgen? De belangrijkste elementen zijn:
1. De tijd voordat het proces daadwerkelijk wordt gestart
2. De tijd die technisch nodig is om een vernieuwing uit te voeren
Het is belangrijk dat we deze problemen kennen, want als we ze begrijpen, kunnen we ze oplossen.
Het test data verversingsprobleem
Uit ervaring zien we dat er minimaal 3 of 4 mensen betrokken zijn bij het verversen van een test database. Waarom? Welke rol hebben ze?
Laten we bij het begin beginnen. Tijdens een ontwikkelproject komt de initiële vraag naar test data van de developers en testers. Ze hebben hun testgegevens nodig en ze willen ook een zekere mate van controle hebben over wanneer een nieuwe testdatabase wordt geïmplementeerd. Productie- en niet-productie databases (lagere omgeving) worden beheerd door de databasebeheerders – een simpele feitelijke verklaring. Zij zijn en zullen altijd de bewakers van de data rijken zijn.
De controle over de databases in de lagere omgeving aan Dev en QA Engineers overdragen is niet iets dat lichtvaardig wordt gedaan. In deze databases staan veel vragen centraal. Hoe groot zullen ze zijn of, beter gezegd, hoeveel ruimte hebben ze nodig? Onthoud dat er een directe correlatie bestaat tussen “ruimte” en “kosten”. Hoe snel zal deze omgeving zijn? Is de noodzaak om te verversen een eerste zorg, zodat het team snel kan terugkeren naar een bekend ontwikkel- of testpunt? Het is duidelijk dat voordat DBA überhaupt zou overwegen om de controle aan anderen over te dragen, er eerst een breder debat moet plaatsvinden.
Maar waarom kost het zoveel mensen en zo veel tijd? Een van de redenen is dat het NIET een van de primaire taken is van veel DBA’s. Vaak komt het aanvullen van de lagere omgevingen op de tweede plaats na productietaken.
Het is logisch dat de kernfuncties van de database, die het bedrijf levend en winstgevend houden, vóór de ontwikkelings- en leveringscycli van applicaties komen. Maar het vertragen van de leverings- en implementatiecycli heeft directe en vaak aanzienlijke kosten voor het bedrijf. Hoe later de ontwikkel- en testcyclus, hoe hoger de kosten voor het identificeren en oplossen van problemen.
Wat is het proces voor het aanvragen van een database-vernieuwing en hoe kan automatisering helpen? Het proces ziet er in de meeste gevallen ongeveer zo uit:
- Eerste aanvraag voor een testdatabase van ontwikkeling of test tot beheer;
- De directie controleert de aanvraag en stuurt deze indien afgesproken door naar de DBA Team Lead;
- DBA-teamleider controleert het verzoek en delegeert een DBA om de databasekopie te implementeren;
- DBA voert de kopie uit en levert deze af.
Gezien de bovenstaande opmerkingen kunt u gemakkelijk zien hoe het proces mensenintensief en afhankelijk van tijdplanning / prioriteit kan worden.

Test data voorziening
Als Development, Test en QA alleen hun eigen test data zouden kunnen beheren, dan wordt een deel van het ‘probleem’ direct aangepakt. De mogelijkheid om een test database op aanvraag te vernieuwen, verwijdert onmiddellijk de meerdere verzoeklagen en bevoegdheden die inherent zijn aan de traditionele omgeving. Dit betekent per definitie dat de implementatietijd specifiek beperkt is tot de tijd die nodig is om de verversing uit te voeren.
Maar wat is er nodig om een dergelijk proces op zijn plaats te krijgen? Het is heel praktisch om te denken dat twee van de DBA-functies met vertrouwen kunnen worden overgedragen aan gebruikers met een lagere omgeving. Ten eerste moet je ervoor zorgen dat de implementatie wordt uitgevoerd zonder enige bedreiging voor de brondatabase(s). De tweede is ervoor te zorgen dat de gebruikte database voldoet aan de voorschriften voor gegevensbescherming en een voetafdruk heeft die binnen redelijke grenzen ligt. Met andere woorden, het gebruik van database-subsetting- en maskeringstechnieken is een inherent onderdeel van het proces. Compliance en good housekeeping-technieken worden standaard geïmplementeerd.
Het is onze ervaring dat DBA graag wil weten wat DATPROF Test Data Management doet en hoe het de verschillende taken uitvoert – maskering, subsetting, geautomatiseerde implementatie. Het duurt niet lang voordat dit begrip wordt gerealiseerd en manifesteert zich snel als een reeks geïmplementeerde projecten die de twee kernconcepten zullen opleveren.
Dit betekent dat DBA’s met een gerust hart een toezichthoudende rol kunnen spelen bij implementaties van databases met een lagere omgeving!
Test data Automation Tools
Eenmaal ontwikkeld, kunnen DATPROF-applicaties worden geautomatiseerd met behulp van DATPROF Runtime. Dit eenvoudig te gebruiken portaal voor serviceaanvragen is toegankelijk via een intuïtieve browserinterface of via een API die wordt beheerd en aangestuurd door automatiseringsservers of taakbeheersystemen. Dit betekent dat het eenvoudig kan worden geïntegreerd met tools zoals Jenkins, ServiceNow, Xebialabs of de Atlassion-suite.
Even belangrijk is dat de interface kan worden geconfigureerd om de gebruikerstoegang tot de maskeer- en ontwikkelingsprojecten te controleren of te beperken. Dit betekent dat een selfservice-leveringsmechanisme snel en met vertrouwen kan worden ingezet. Het eindresultaat is dat je het knelpunt van test data aanpakt door je gebruikers de juiste test data op de juiste plaats en op het juiste moment aan te bieden. Je geeft ze wat ze willen, wanneer ze het willen!
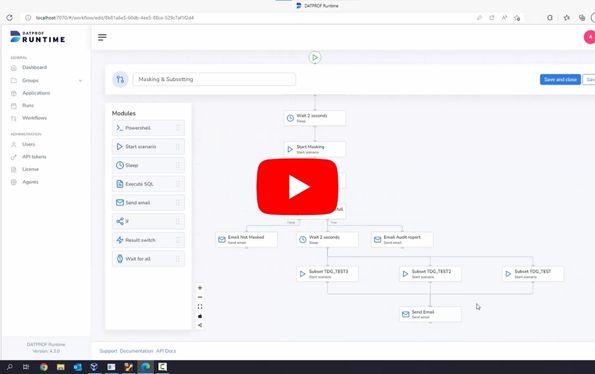
Het hebben van één Test Data Management-portaal is cruciaal voor automatisering van test data. Stel je voor dat je het subsetten, maskeren en genereren van test data vanuit één portaal kunt uitvoeren en monitoren. Vanuit deze portal kun je test data inzetten voor meerdere teams en omgevingen tegelijk. Portalgebruikers loggen in en verversen hun eigen test data omgeving en voeren meerdere processen uit. Het is de meest efficiënte manier om test data te genereren die je maar kunt bedenken.
DATPROF Runtime
![]()
![]() Ververs omgevingen via een self-service portaal
Ververs omgevingen via een self-service portaal![]()
![]() Automatiseer processen met events en triggers
Automatiseer processen met events en triggers![]()
![]() Bouw uitgebreide workflows met behulp van drag-and-drop
Bouw uitgebreide workflows met behulp van drag-and-drop![]()
![]() Integreer in je CI/CD pijplijn met de REST-API
Integreer in je CI/CD pijplijn met de REST-API![]()
![]() Integreer vanuit Bamboo, Jenkins, SeviceNow etc.
Integreer vanuit Bamboo, Jenkins, SeviceNow etc.![]()
![]() Roles and permission management met active directory integratie
Roles and permission management met active directory integratie
De impact van een subset
Het aanmaken of verversen van een database kost tijd. Zoals aan het begin van dit artikel vermeld, kost het aanmaken zelf, het kopiëren van een database, tijd. Deze tijd kan op veel manieren worden verbeterd: meer CPU-vermogen, meer geheugen, snellere I/O-subsystemen zouden altijd helpen. Een simpel feit blijft: hoe groter de brondatabase, hoe meer tijd het kost om een nieuwe database te maken in de lagere omgevingen. Grootte doet er toe. Hieruit volgt dat het werken met subsets van productiedatabases een aanzienlijke invloed zal hebben op de implementatietijd in deze regio's. Hoe kleiner de database, hoe sneller een database kan worden aangemaakt. Waarom subsetten zo relevant is, wordt besproken in ons artikel over data subsetting.
Book a meeting
Schedule a product demonstration with one of our TDM experts
Full Platform Demo
45-minute session to discover the entire TDM platform with the help of a technical pre sales consultant.
![]()
![]()