Synthetische data generatie
Het gebruik van privacygevoelige (productie) data voor het testen van software is tegenwoordig niet alleen ouderwets, het is ook niet toegestaan door de privacy wet- en regelgeving als AVG, PCI en HIPAA. Maar voor de beste softwaretests heb je test data nodig die “productie-achtig” is, toch?
Dus hoe zorg je ervoor dat jouw data enerzijds representatief is, maar anderzijds niet herleidbaar tot een natuurlijk persoon? Het antwoord: data anonimiseren en het genereren van synthetische test data – het beste is de combinatie van deze twee methoden.
Wat is synthetische test data?
Synthetische test data zijn ‘nep / dummy’ gegevens die kunnen worden gebruikt voor softwareontwikkeling en testen. Het is niet gebaseerd op echte, bestaande informatie: het is kunstmatig gecreëerd met behulp van algoritmen. Kort gezegd zijn er twee belangrijke redenen waarom synthetische test data wordt gegenereerd: 1) Synthetische gegevens worden gebruikt om privacygevoelige informatie te vervangen of 2) ze worden gegenereerd om te voldoen aan specifieke behoeften of bepaalde voorwaarden die mogelijk niet in de productiegegevens voorkomen.
Synthetische data wordt ook wel nepdata, dummy-data, nepgegevens of voorbeeldgegevens genoemd. We noemen het hier gewoon synthetische data. En wat we bedoelen met synthetisch gegenereerde test data zijn gegevens:
- die zijn afgeleid van een seed-file;
- die willekeurig zijn gegenereerd, of
- die zijn gegenereerd op basis van logica.
Data anonimiseren met synthetische data
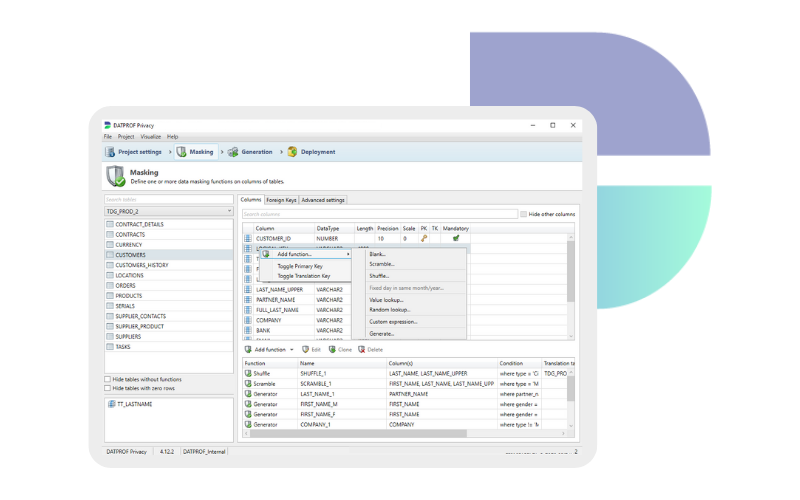
Met data maskering kun je een template maken en maskeringsregels implementeren zoals shuffle en blank om data te maskeren. Soms is dat echter niet voldoende om er absoluut zeker van te zijn dat de gegevens niet meer herleidbaar zijn tot een natuurlijk persoon. En als je te veel maskeringsregels gebruikt, zijn de gegevens mogelijk niet meer representatief. In deze gevallen kun je besluiten om synthetisch gegenereerde testgegevens te gebruiken als onderdeel van je maskeer template. Je kunt privacygevoelige data zoals namen, e-mailadressen en bankrekeningnummers vervangen door synthetische testgegevens. Dit zal je ook helpen bij het afstemmen van je test data op je testcases.
Synthetische data generatoren
in DATPROF Privacy
Basic
- Random string
- Random date/time
- Random number
- Random decimal number
- Sequential numbers
- And more…
Names
- Brand
- Company
- Male First name
- Female First name
- Last name
- Location
- Country Code
- City
- Street
- Country
- And more…
Business
- BSN (Dutch Social Security Number)
- IBAN
- Currency Code
- Currency Symbol
- And more…
Advanced
- Random value from seed file (Pick values from a custom CSV seed file)
- Regular expression (Generate values based on a regular expression)
- And more…
Synthetische data genereren ‘from scratch’
Hoewel er veel wordt gezegd over het gebruik van synthetische data als anonimseer techniek, mag de noodzaak van het genereren van data ‘from scratch’ niet worden vergeten. Als je een app ontwikkelt voor een gloednieuw systeem waarin je nog geen data hebt, valt er niets te maskeren. Maar toch heb je test data nodig om te controleren of de app werkt met ‘productie-achtige’ data. Of je hebt bepaalde hoeveelheden data nodig die je niet hebt. In deze gevallen kun je test data genereren. Je bepaalt zelf wat voor soort data (kolommen, tabellen) je nodig hebt en met een synthetische data generatie tool vul je deze tabellen met representatieve, realistisch ogende data.
Hoe genereer je synthetische data
De meeste database specialisten weten hoe ze test data moeten maken, maar het kost te veel tijd om dit regelmatig handmatig te doen. Daarom groeit de vraag naar synthetische test data. Het maken van testgegevens moet een middel zijn om een doel te bereiken. Niet het doel op zich.
Synthetische test data kan worden gemaakt met een test data generator. Er zijn enkele gratis generatoren die kunnen worden gevonden met een eenvoudige zoekopdracht op internet. Voor een eenvoudige klus, zoals het genereren van een tiental voornamen, is dit een prima optie. Als je echter een tabel hebt met meerdere kolommen die ook relaties heeft met andere tabellen, wordt dit al snel een onmogelijke en onbetrouwbare taak met een open source data generator.
Het genereren van testgegevens op zich is niet het meest gecompliceerde onderdeel. Algoritmes doen dit voor ons. Maar wat het uitdagender maakt, is ervoor zorgen dat de gegevens zich binnen een database goed blijven gedragen, zodat ze kunnen worden gebruikt voor goede tests. Net als data maskeren, heeft het genereren een planning en zorgvuldige configuratie nodig, met name bij het definiëren van de startwaarden van de primaire sleutel (primary key) of enige andere unieke beperking die in een tabel is geïmplementeerd. Daarom heb je een van de gelicentieerde tools voor het genereren van synthetische gegevens op de markt nodig. Over het algemeen hebben deze tools veel meer mogelijkheden en bieden ze technische en functionele consistentie – onmisbaar voor goed ontwikkel- en testwerk.
Test data generatie voor jou database
Wanneer je hebt besloten om synthetisch gegenereerde data te gebruiken voor testen, moet je weten hoe je data moet genereren zodat deze in jouw database passen. Met DATPROF Privacy is dat heel eenvoudig omdat het niet alleen een hulpmiddel voor het anonimiseren van gegevens is, maar ook een hulpmiddel voor het genereren van data. Het levert realistische test data inhoud en -volume.
Zodra je DATPROF Privacy aan je database hebt gekoppeld, voeg je gewoon een generatiefunctie toe zoals elke andere functie in je maskeer template en genereer je gegevens voor die kolom in jouw database. Je kunt ook nieuwe kolommen toevoegen en ‘from scratch’ synthetische gegevens genereren.
Een groot voordeel van deze aanpak is dat alle bestaande relaties tussen de tabellen ongewijzigd blijven. Je datastructuur blijft functioneel en technisch consistent, maar je gebruikt synthetische data in plaats van privacygevoelige productiedata. Uiteraard ondersteunen we ook het genereren van test data over een keten van systemen. Dit doen we met behulp van vertaaltabellen of met behulp van ‘Deterministic Masking’.
Book a meeting
Schedule a product demonstration with one of our TDM experts
Full Platform Demo
45-minute session to discover the entire TDM platform with the help of a technical pre sales consultant.
![]()
![]()
FAQ
Wat is synthetische test data?
Met synthetische test data wordt – nep – data gegenereerd die gebruikt kan en mag worden voor het testen van software. Het bevat geen privacygevoelige informatie aangezien het niet echt is.
Wat is het synthetische test data generatie?
Het genereren van synthetische test data is het proces van willekeurige data creatie (vanaf nul of ter vervanging van bestaande data) met behulp van een tool voor het genereren van test data.
Hoe genereer je test data?
Synthetische data kan handmatig of met behulp van een generatie tool worden gegenereerd. Dit laatste is de beste optie als je datavolumes nodig hebt die je niet hebt.
Wat zijn de voordelen van synthetische testgegevens?
- Minder data gebruiken
- Perfect afgestemd op je test cases
- Geen risico op datalekken
- Beperkte afhankelijkheden
- Bespaar op opslagkosten en bijv. licenties
What are the cons of synthetic test data?
You need to keep in mind all the necessary attributes for your system. You need to know how many attributes your data model (not database) has, the functional requirements of your systems, data quality issues, historical data, and so on.