GDPR one year later
Is the importance of data masking overrated?
It has been a year since the full implementation of the GDPR. In the meantime we’ve seen a lot of effects of the GDPR that are doubtful. From photos that may no longer be published, people who put green dots on their foreheads so that someone knows that photos may or may not be published. A lot of weird stories are circulating. Now that the dust has settled, we want to take a look at what actually happened in the past year with regard to the GDPR in relation to test data.

General Data Protection Regulation (GDPR)
Our right to privacy is part of the European Convention on Human Rights. This convention states that everyone has “the right to respect for his private and family life, his home and his correspondence”. Various privacy laws have been adopted on this basis. With the current IT systems and the rise of social media, the old legislation was no longer adequate enough. That’s why the GDPR was introduced: the newest EU law on data protection and privacy for all individual citizens in the European Union (EU) and the European Economic Area (EEA). If you’re interested in the full GDPR regulation, you can consult it here, but we made it a little easier with a summary of the basic rules:
1. Obtaining consent
Your terms of consent must be clear. This means that you can’t stuff your terms and conditions with complex language designed to confuse your users. Consent must be easily given and freely withdrawn at any time.
2. Timely breach notification
If a security breach occurs, you have 72 hours to report the data breach to both your customers and any data controllers, if your company is large enough to require a GDPR data controller. Failure to report breaches within this timeframe will lead to fines.
3. Right to data access
If your users request their existing data profile, you must be able to serve them with a fully detailed and free electronic copy of the data you’ve collected about them. This report must also include the various ways you’re using their information.
4. Right to be forgotten
Also known as the right to data deletion, once the original purpose or use of the customer data has been realized, your customers have the right to request that you totally erase their personal data.
5. Data portability
This gives users rights to their own data. They must be able to obtain their data from you and reuse that same data in different environments outside of your company.
6. Privacy by design
This section of GDPR requires companies to design their systems with the proper security protocols in place from the start. Failure to design your systems of data collection the right way will result in a fine.
7. Potential data protection officers
In some cases, your company may need to appoint a data protection officer (DPO). Whether or not you need an officer depends upon the size of your company and at what level you currently process and collect data.
Breaches
The Netherlands: 12.763
United Kingdom: 5.992
Germany: 1.929
France: 1.000
Italy: 305
Portugal: 123
Denmark: no data
Highest fines
United Kingdom: €203.000.000
France: €50.000.000
The Netherlands: €600.000
Portugal: €400.000
Denmark €180.000
Germany: €80.000
Most complaints
United Kingdom: 33.089
Germany: 14.878
France: 9.700
The Netherlands: 9.661
Italy: 2.944
Portugal: 186
Denmark: no data
Even while the GDPR is in place all around Europe, there are quite some differences regarding to the approach of authorities. Some of them are still in the informing phase, some are already fining organizations. In the Netherlands the breach notifications are quite high compared with the other countries. The reason for this might be that a year before the GDPR was in place, The Netherlands already had a new legislation that also concerns breach notifications.
GDPR and test data trends
We see some new test data developments now that the GDPR is fully implemented:
- Importance of information security in noticed
- Synthetic test data vs masked test data
- Maturity model of test data
- Subsetting to mitigate risks
- New parties
1. Importance of information security in noticed
There never really was enough budget available to really make information security important. With the help of the GDPR we really see that information security is getting more important. There is plenty of attention for securing information systems. From privacy by design or default to “two-way authentication”. You also see an important theme in role separation and who can see which information. It is striking that a lot of DPOs (data protection officers) focus mainly on production environments, trying to make sure these are as secure as possible. Over the past years we’ve seen that for every production system there are multiple copies of production in non-production environments. And often these environments are less secure because of their purpose, otherwise they will be difficult and slow to work with.
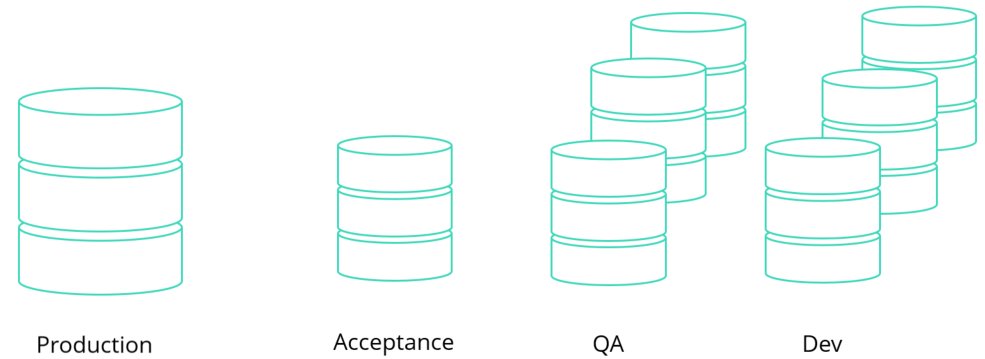
In many cases we see that for every production system there are at least three other environments: acceptance, QA and Dev. These environments often have a much lower security level. This is something that you should be aware of and it has to change!
2. Synthetic test data vs masked test data
We want to make sure that when we take software into production, this software actually does what we expected. This is the reason we measure software quality. In a DevOps world it becomes even more important. The question is: do we use synthetic test data or masked test data to test the software?
In the last year we noticed an increasing desire for synthetic test data. Synthetic test data is of course a beautiful solution in relation to GDPR. With synthetic test data you know for sure that test data is fictional and that you thereby 100% comply with GDPR. The disadvantage of anonymizing or masking test data is that there is still a possibility that a combination of factors can be traced to a natural person.
The major disadvantage of synthetic test data is the lack of representativeness. Often a test data is thought to have a test case and you want to cover it. But certainly in corporate environments where you often see that the database is:
- Filled with historical test data;
- Filled with migrated test data;
- Often containing systems with a lot of tables (more than 500).
Synthetically filling these databases is a huge job. You not only need a lot of technical knowledge, it is also a lot of work that takes a lot of time. We do see that there are a lot of parties who say they can do this. But in reality we see only a few parties that actually give substance to the realization of synthetic test data generation.
3. Maturity model of test data
The techniques for masking or anonymizing data are becoming more and more mature. Not so long ago, data was made anonymous with relatively few masking functions. But with the pressure of the GDPR you can see that the functions are becoming more extensive. And that the templates are also becoming more complex. To make it more specific, masking data is becoming more mature because individual cases are becoming easier to anonymize.
In general, we see that professional solutions are increasingly combining masked and synthetically generated test data. On the one hand to comply with the GDPR (to remove more traceability from a data set) and on the other hand to ensure that test data are better aligned with test cases. By cleverly manipulating test data cases you are also able to, for example, manipulate data so that it perfectly matches test cases.
4. Subsetting to mitigate risks
Although it is still minimal, we see that subsets become part of the GDPR solution of organizations. This may seem a bit strange, but it is a smart way to make data unavailable. After all, data that is not available cannot be leaked. It helps in the reporting obligation, since if you leak data, then you may have to report this to the individual affected. If there is less data, so no full copy production, then you have a lot less work. This is one of the reasons organizations choose to subset test data as part of their GDPR program for test data.
5. New parties
More and more small players, working on test data, are entering the market. That is a good development. This ensures the necessary intensity on the market and gives customers more choice. The pressure on prices is therefore also better. Although the price should not be more important than quality.
Conclusion
In recent years we’ve seen increasing emphasis on the subject of test data management at DATPROF. And by masking and anonymizing test data specifically on the subject of the GDPR. There will still be some emphasis on this in the near future, and customers will look for more solutions in this area. The GDPR will continue to cause more pressure. The importance of masking test data is definitely not overrated!
Our general tip to anyone looking for a data masking solution: choose a party that follows the developments. It is important that adjustments can be made. You don’t want to have to replace your current toolset with a new one, with all the implementation work it involves.