Data masking
Written by Maarten Urbach
Most organizations use dozens of databases and applications for their processes. It´s common to copy these (production) databases to another environment, for other uses like development, testing, acceptance, training, outsourcing, etc. However, a lot of these systems contain personally identifiable information (PII) or corporate critical and privacy-sensitive data, which you can’t use for such purposes.
Data masking or anonymization revolves around altering the data in a way that the data remains useful for testing and development, but the identification of a person becomes almost impossible. This article explains the basics of data anonymization and what you can do today to start moving towards anonymized non-production environments to protect your PII data.
What is data masking?
“Masking or obfuscating data is the process of transforming original data using masking techniques to comply with data security and privacy regulations.“
Data masking meaning is the process of hiding personal identifiers to ensure that the data cannot refer back to a certain person. The main reason for most companies is compliance. There are different methods for masking data and data masking techniques. Also, a distinction can be made between dynamic data masking and static data masking. The method or technique you choose depends on the type of data you want to mask.
Terminology
There are different terms used interchangeably for the definition of data masking, like data anonymization, data scrambling, data de-identification, or data obfuscation. Data pseudonymization is not part of this lineup since with this method re-identification is possible. Pseudonymized data therefore still falls under the scope of privacy legislation. Data may only be labeled as anonymized when any future re-identification is prevented.
Why should I mask my data?
Anonymizing or scrambling production data within non-prod environments is used more and more often. You still have your full data set containing ‘normal’ data, but in the masked data, all sensitivities are modified so they cannot be linked to the original individual.
There are several reasons why organizations start masking their data:
- It is a solution to risks like data leakages, data loss, and data breaches;
- When data is masked, it helps to get compliant with laws and regulations;
- Protect sensitive data. Masked data is essential for protecting and securing data against competition;
- It helps to have representative data for software development and quality purposes (and training, Business Intelligence, or marketing).
The process isn’t just blanking data fields, it is transforming PII into characteristically irreducible data.
The advantages and benefits
Masked data offers several advantages, but the key reason for organizations is the reduction of data security vulnerability. Protecting customers and citizens is getting more regulated, and new data regulations are being created or updated. Using obfuscation on personal information or, in other words, hiding personal identifiers, ensures that software development and software test teams can access the data with a highly reduced risk.
The challenges
Masking data is an operation in itself and it needs attention, especially when you have complex data. The first challenge to overcome is masking private data irreducibly while keeping it as characteristic to production (quality) as possible. In other words: make it untraceable and keep it usable for testing. The second challenge is to mask the data consistently over multiple systems and databases. The third is coping with triggers, constraints, business rules, and indexes while executing the transformations.
How to become compliant with data protection laws like GDPR?
Copying a database means that you now have to secure not one database but all the copies as well. That´s why most governments stated data privacy laws to protect customers/civilians from wrongdoing. Not protecting their information, you’ll risk the following:
- Not complying with laws and European Union directives concerning data security
- Exposure of personal information to unauthorized users (employees)
- Image loss because of bad publicity when data is leaked
- Customers terminate their relationship because of a lack of trust in security since their data is not protected well
How to mask data?
The first thing you need to do is discover whether you have personal information in your databases at all. If you do, how sensitive is this data? The sensitivity and the rules related to the sensitivity vary from country to country. A name in itself is not as sensitive as a person’s address. The sensitivity isn’t (in most cases) in identifying data. The sensitivity comes with what we call characteristic or descriptive data.
Start by identifying the systems that contain personal data. When you know which systems contain personal data, then you can get into more detail. What data does this particular system contain and what do we want to do with it? What data needs protection, and encryption? What action to take depends on a couple of things. First is the information security policy. Most organizations have such a policy. Some policies prescribe the baseline for data that should be anonymized. On the other hand, you have the needs of the testing community.
When is information privacy sensitive?
A name is personal, not necessarily privacy sensitive. The residence isn’t private as well. It is public information. A mere search on Google will reveal this information easily. whether someone has an illness or is €500.000 in debt makes the data valuable and sensitive. What you want to do is keep the descriptive data, but cut the link with the actual person. This is done by changing the identifying data.
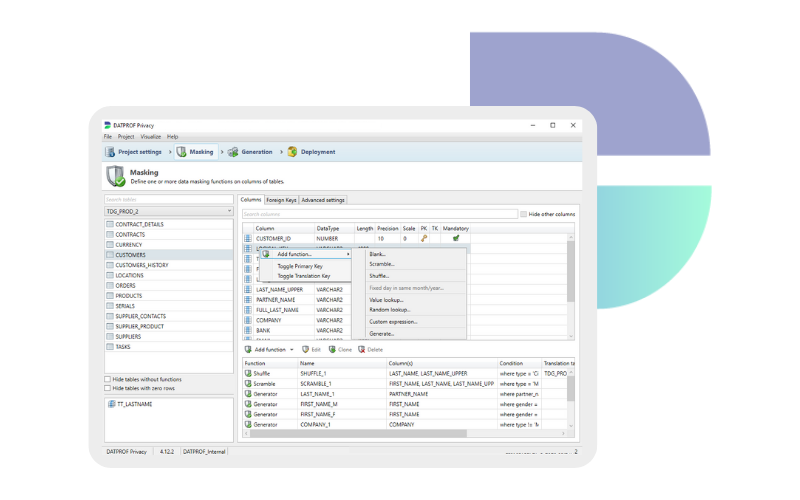
What kind of masking methods are there?
When you have determined which information should be masked or anonymized, you can choose the method you want to use. In general, we see two data masking technologies to anonymize data, namely synthetic data generation and data masking (or data obfuscation). Data masking uses functions like data shuffling, scrambling, and others. You can distinguish the two methods or techniques by stating that masking is the reuse or modification of data in the databases and that generation is the creation of data that does not yet exist.
The third method is a combination: generate synthetic data as a masking technique to replace existing data. The big advantage of this is that schemas and structures of the original data are preserved when replacing sensitive data with synthetically generated data.
Techniques
When you’ve determined which data needs to be anonymized, you can start specifying how it should be anonymized. The development of the masking template starts. What anonymization rules are you going to use?
Shuffle
A shuffle takes the distinct values of one or more columns and rearranges them randomly. For example, by shuffling first and last names separately, you get new first/last name combinations.
Blank
The blank function is self-explanatory. The blank removes (blanks) a column. This leaves no data, so this data masking technique is only usable for columns not used in testing.
Scramble
The scramble function replaces characters by x and numbers by 9. This function leaves no recognizable data, so the scramble gives a result that can’t be used by testers functionally.
First Day in Month/Year
This first-day function makes it possible to change the date of birth to the first of the month or year. By doing this, there is less variation and therefore it is harder to find a specific person.
Random Lookup
A random lookup uses a reference table to replace values by randomly selecting data from another table. This can be useful if you want to add test cases to existing data. For example, your data doesn’t have any diacritics and you want to add these to the first name data.
Value Lookup
The value lookup uses a reference table as input to anonymize the values in a table. It needs a reference key, i.e. a customer id, to find the right data. It is commonly used as part of a setup that keeps data consistent. Most of the time this setup also uses a translation table.
Custom Expression
The standard functions may not suffice in all situations. To add some extra flexibility you can use the custom expression function. This gives you the possibility to build your own functions. Whether this is the composition of an email address or something much more advanced.
Data Generation
DATPROF Privacy also has built-in synthetic data generators which replace the existing privacy-sensitive data with synthetically generated (fake, dummy) data. It depends on your test needs if you want to use masking functions, generate synthetic data, or a combination of these to anonymize your data.
Data scrambling examples
When you deploy data scrambling rules to data you’ll end up with representative though unrecognizable data. There are many techniques that can be used. Watch the video to see some data scrambling examples and how to mask PII data.
Mask test data end-to-end
In today’s databases, some values are stored more than once. The complexity starts when (test) data should consistently be masked over multiple systems. For example, a person’s name might be stored in the customer table as well as in the billing table. For end-to-end testing, it is vital that data is masked in the same order in every source and application.
Using a translation table
A translation table keeps a copy of the old value (i.e. the original first name) and the new value (i.e. the shuffled first name) of an anonymization function. It also adds the primary key value(s) of the anonymized table. These keys can be used in other functions to find the right anonymized value in the translation table, so another table can be anonymized in the same manner. This enables consistent anonymization throughout a database/application or chain of databases and applications.
Security
Your translation tables contain the original values. We therefore advise clients to treat translation tables as if they contain production data. To minimize the risk, you could place any translation tables in a separate schema with a separate privilege scheme. Going one step further, you could anonymize data on one database and distribute test sets from there, rather than having developers directly access potentially sensitive data.
Deterministic data masking
Another way to mask test data consistently over multiple systems or (cloud) applications is with deterministic data masking. With deterministic masking a value in a column is replaced with the same value whether in the same row, the same table, the same database/schema, and between instances/database types. Thanks to deterministic masking, no translation tables are needed anymore.
Best practices and tips for
data masking
There are a number of best practices for data masking. The first one is: to discover where privacy-sensitive data is stored. Gain insight! Without it, it’s impossible to start. There are some specific data type connections that are more sensitive than others, like date of birth and postal area. Research shows that if this data isn’t masked, you’re pretty identifiable.
A wise man once said, “If you’re failing to plan, you’re planning to fail.” That’s the second best practice. Don’t start without a plan. We have a Data Masking Project Plan that might be very helpful for that.
Start analyzing where data is stored and discuss the masking rules with the CISO (Chief Information Security officer) or DPO (Data Protection Officer). Tell them that replacing data with only ‘xxxxxx’ isn’t going to help the business. Just discover where common grounds can be found.
And maybe to most important data masking tip: try to start simple. We see many organizations blowing up the data masking project. Don’t. That would be a really time-consuming job. Just start in a simple manner and improve along the way. Doing nothing is even worse. So even if your first masking run isn’t 100% perfect – it is better than nothing!

Data masking tools
There are many, many data masking tools – or data obfuscation tools. What we distinguish ourselves in is the ease of use of our product DATPROF Privacy and customization service. Every customer and every masking need is different, demanding different approaches. Therefore, every organization needs a custom-made template, which we help to develop in the initial PoC phase. The ease of use of the database masking tool allows the customer to make changes and develop a template of their own.
Database masking
DATPROF applies to the software lifecycle of the database vendors. We want to make sure you can provide obfuscated data in the sources, applications, or databases of your choice. That’s why we have integration for the latest versions of all major relational DB’s as shown in the table below. If your platform isn’t listed, it doesn’t mean that we don’t support it – in most cases, we find a way to make it work (or we develop additional support for database scrambling).
| Oracle | 11.2 and above | » More info |
| Microsoft SQL Server | 2008 | 2012 | 2014 | 2016* | 2017* | 2019* | » More info |
| DB2 LUW | 10.5 and above | » More info |
| DB2 for i | 7.2 and 7.3 | » More info |
| PostgreSQL | 9.5 | 9.6 | 10.5 | 11 | 11.2 | 11.6 | 12 | 12.1 | » More info |
| MySQL | 8.0 | » More info |
| MariaDB | 10.4 |
* Check the Powershell module remarks
Book a meeting
Schedule a product demonstration with one of our TDM experts
Full Platform Demo
45-minute session to discover the entire TDM platform with the help of a technical pre sales consultant.
![]()
![]()
FAQ
What is data masking?
Data masking is the process of hiding personal or privacy-sensitive data. The main reason is to ensure that the data cannot refer back to a certain person.
Why data masking?
To protect personally identifiable information, data needs to be anonymized before using it for purposes like testing and development.
How to mask data?
Data can be masked with the help of masking rules (shuffle, blank, scramble) and synthetic data generation. A good data masking tool combines several techniques to build a proper masking template.
What data masking techniques are there?
Shuffle, blank, and scramble are the best-known and simplest techniques. More ingenious masking techniques are lookups, custom expressions, and replacing data with synthetically generated (fake) data.
When is data privacy sensitive?
A name is personal, but not privacy sensitive. The city that you live in is also not privacy sensitive. It is public information. But the fact that you have a huge debt or a disease makes your data privacy sensitive.
What is deterministic data masking?
With deterministic masking a value in a column is replaced with the same value whether in the same row, the same table, the same database/schema, and between instances/servers/database types. This way you can easily mask the data consistently over multiple systems.
About the writer
Maarten Urbach has spent over a decade helping customers enhance test data management. His work focuses on modernizing practices in staging and lower level environments, significantly improving software efficiency and quality. Maarten's expertise has empowered a range of clients, from large insurance firms to government agencies, driving IT innovation with advanced test data management solutions.
