Data subsetting
Shifting towards agile software testing with data subsets
We all strive to shorten the time-to-market of our software. With this goal in mind, we start to automate tests, develop in agile and/or scrum teams, start with Continuous Delivery, and so on. All these methods can be successful – can. The successes of these methods depend on your old architecture and infrastructure. We need to innovate the way we use our current infrastructure. The DTAP architecture we use nowadays hasn’t significantly changed since its inception in the nineties. Software development has changed quite a lot, however, requiring us to innovate our non-production environments and their architecture.
Test data preparation
What is data subsetting?
Test data subsetting is extracting a smaller sized – referential intact – set of data from a ‘production’ database to a non-production environment. Many customers ask us: “How should we create a subset?” and “How usable is a subset compared to my copy of a production database?” The concept of data subsetting is surprisingly simple: take a consistent part of a database and transfer it to another database. That’s all. Of course, the actual data subsetting isn’t that simple. Especially selecting the right data for the job is tricky, whether it’s testing or development. Why? Because you need to filter data. The complexity is in getting all the right data to create a consistent dataset over all tables that also fulfills the tester’s needs.
Why subset your test data?
At the moment most organizations use production copies for test and development. When asked, these organizations often use arguments like: “This is the easiest way of working” or “Only production data contains all test cases” or “We can only thoroughly test using production data”. These arguments might be valid in some (test)cases, but there are reasons not to use full production copies:
- The available time-to-market is getting shorter, because ‘The Business’ demands it and the lifecycle of software also shortens.
- Methods like Scrum, Agile, or DevOps are mostly aiming to deliver the right software faster. However, faster delivery requires higher demands on environments to support this. Large (sometimes huge) production copies aren’t helpful in achieving this.
- Your production environment grows over time, and the size needed in non-production environments grows twice as fast if you keep using full copies of production. For example: going from a production size of 1 terabyte to 2 terabytes results in 2 TB in Acceptance + 2 TB in Test + 2 TB in Development = 6 TB of total increase outside of production.
Without question, most organizations don’t need all the data they have stored in their non-production environment and it’s costing them money.
With the use of subsets:
- The need for data storage is decreased (sometimes by more than 90%)
- Idle times are significantly reduced
- High control in test and development turnarounds
- Developers influence the data they need
Also read: 5 reasons to start subsetting
Creating a subset
So how do we create a useful subset? First of all, I think we need to change the way we look at (test) data. We need to look at data the same way science does. In research using samples is common sense, it just isn’t feasible to interview the complete population of the USA or Holland. Of course, the sample needs to be representative! Based on that sample population, something can be said or concluded about the complete population. We should approach (test) data in the same way. Carefully choose test data as a representative sample and use it. Most of the time this needs some tweaks, but experiment (test) and learn from the results!
Many of our customers use filters based on a number of well-known test cases and if needed complemented with a random percentage of the production data on top of that. As you can see, the core of the subset is filled with known test cases, thus based on knowledge coming from the testers and developers. So in the end developers and testers influence their test data. Often this results in a smaller dataset. With the use of subsets, we see that it´s possible to reduce a production database of 6 terabytes to 60 gigabytes!
Test data preparation tools
With DATPROF subset you can extract specific selections out of multiple production databases and make them directly available within the test environments. DATPROF Subset selects data from a full-size production database – in DATPROF Subset this is the “Source database”. This data goes to a copy (test) database. In DATPROF Subset this is called the “Target database”. By applying filters when filling the Target database, this database will be smaller in size than the Source database. This enables faster and cheaper testing.
Data extraction methods
The main method DATPROF Subset uses is to access the data via one central table in the database. This table is called the start table. Other data content is extracted based upon a Foreign Key relation with the start table.
During deployment of the subset project, only a connection between the source and the target database is needed. No data passes through DATPROF Subset. This has a favorable impact on performance.
Data preparation examples
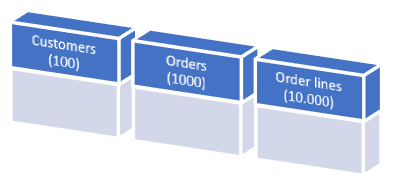
The example below shows three tables. There are 100 customers, 1000 orders, and 10000 order rows in the source database. Every customer has 10 orders and every order has 10 related order_details. Only 10 customers have a name starting with ‘A’.
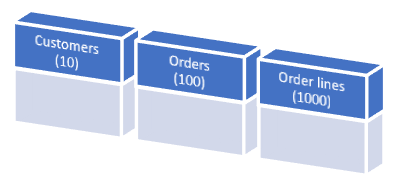
If the customer’s table is the start table and we only select customers having a name starting with an ‘A’, this will result in a target database with 10 customers, 100 orders, and a total of 1000 order_details.
The following result is a target database that is 90% smaller than the source database, retaining the data consistency.
Test data management
DATPROF Subset enables the user with features to save the defined filters, rules, and different functions, so they can be deployed repeatedly. This way a controlled subset process emerges. After data subsetting, the data in the target database can be used for testing purposes, but can also be the secure base for anonymizing the data using DATPROF Privacy. Both subsetting and masking can be automated and integrated into your CI/CD pipeline with the help of DATPROF Runtime.
See Data Subsetting in Action
Watch the demo and learn how to subset your non production databases, manually or automated.